
{kind=link}
The rapid proliferation of large language model applications has created a critical challenge for enterprise technology leaders: how do you know whether your AI system is actually performing safely, accurately, and reliably and how do you prove it to regulators, auditors, and customers? The answer lies in rigorous, systematic evaluation. But evaluation of LLMs is a fundamentally different discipline from conventional software testing, and organizations that approach it with traditional quality assurance methods consistently discover blind spots that expose them to significant risk. A purpose-built LLM evaluation platform, combined with expert AI evaluation consultation, is the solution that leading enterprises are turning to.
Why LLM Evaluation Is Different
Evaluating a large language model application is not like evaluating a deterministic software system. Traditional software either produces the correct output or it does not the test suite is relatively straightforward to design, and pass/fail criteria are usually clear. LLMs operate in a fundamentally different paradigm. Their outputs are probabilistic and context-dependent. The same input may produce different outputs on different runs. ‘Correctness’ is often a matter of degree rather than a binary property. And the failure modes hallucination, bias, harmful content generation, factual inaccuracy, prompt injection are qualitatively different from the bugs that conventional testing is designed to catch.
This means that evaluating an LLM application requires a specialized methodology. You need evaluation frameworks designed specifically for language model behavior, metrics that capture the dimensions of performance that matter for your use case, adversarial test suites that probe known failure modes, and the statistical rigor to draw meaningful conclusions from probabilistic outputs. Building this capability internally from scratch is time-consuming and expensive which is precisely why many organizations are turning to dedicated platforms and expert consultation.
What a Best-in-Class LLM Evaluation Platform Provides
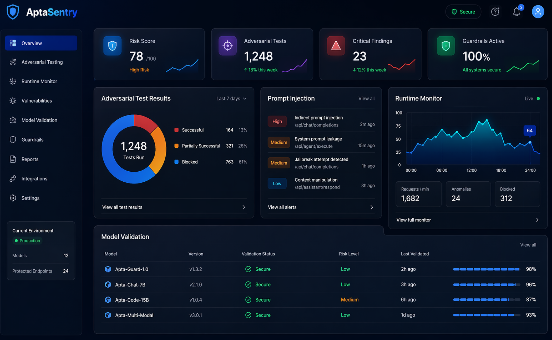
A best-in-class LLM evaluation platform does far more than run a fixed set of benchmark tests. It provides a comprehensive suite of evaluation capabilities that can be adapted to the specific requirements of your deployment context, use case, and risk profile.
Core capabilities should include automated adversarial testing systematic probing of the model against known attack classes including prompt injection, jailbreaking, and data extraction attempts. They should also include behavioral consistency analysis, assessing whether the model produces stable, predictable outputs across variations in input phrasing. Factual accuracy evaluation, bias detection, and harmful content analysis round out the essential evaluation dimensions for most enterprise use cases.
Beyond these core capabilities, the platform should support custom evaluation development. Every enterprise deployment is unique, and a platform that only offers pre-built, generic evaluations will inevitably leave important dimensions of your specific system untested. The ability to define custom evaluation criteria, integrate proprietary test data, and configure evaluations to match your specific compliance requirements is essential for mature enterprise evaluation programs.
Continuous evaluation is another critical capability. Models change through fine-tuning, through changes in retrieved context, through updates to integrated tools and APIs. An evaluation program that only assesses the model at initial deployment will miss the behavioral drift that occurs over time. The most valuable LLM evaluation platforms provide continuous monitoring and automated regression testing that ensure every meaningful change to the system is evaluated before reaching production users.
The Role of AI Evaluation Consultation
Even with a powerful platform in place, the complexity of LLM evaluation means that expert AI evaluation consultation adds substantial value particularly for organizations that are newer to systematic AI quality assurance or that are operating in high-stakes regulatory environments.
Experienced AI evaluation consultants bring several capabilities that are difficult to replicate internally. They have deep familiarity with the full taxonomy of LLM failure modes and the evaluation methodologies best suited to detecting them. They can translate regulatory requirements from NIST AI RMF, ISO/IEC 42001, the EU AI Act, or sector-specific frameworks into concrete evaluation programs. And they have the cross-industry perspective to identify risks that are less obvious within a single organizational context.
Consultation is particularly valuable at key inflection points: during initial system design, when evaluation architecture decisions have the greatest downstream impact; before major model updates or production deployments, when a fresh adversarial perspective is most valuable; and during regulatory engagement, when organizations need credible expert assessment to support their compliance representations.
Building an Evaluation-First AI Program
The organizations that will navigate the AI era most successfully are those that treat evaluation as a first-class discipline, not an afterthought. This means embedding evaluation into the development lifecycle from the earliest stages, establishing clear evaluation criteria before deployment rather than discovering requirements after an incident, and building the institutional knowledge and tooling to make continuous evaluation sustainable over time.
AptaSentry combines a powerful LLM evaluation platform with the expert AI evaluation consultation services that help organizations build these capabilities systematically. Whether you are evaluating a customer-facing language model application, an internal enterprise knowledge system, or a complex multi-model pipeline, the combination of purpose-built tooling and expert guidance delivers the depth of assurance that high-stakes AI deployment demands. In a landscape where AI system failures can carry serious financial, regulatory, and reputational consequences, rigorous evaluation is not an optional extra it is the foundation of responsible AI deployment.